Average Number of Years Lost For People Who Died of Coronavirus in China
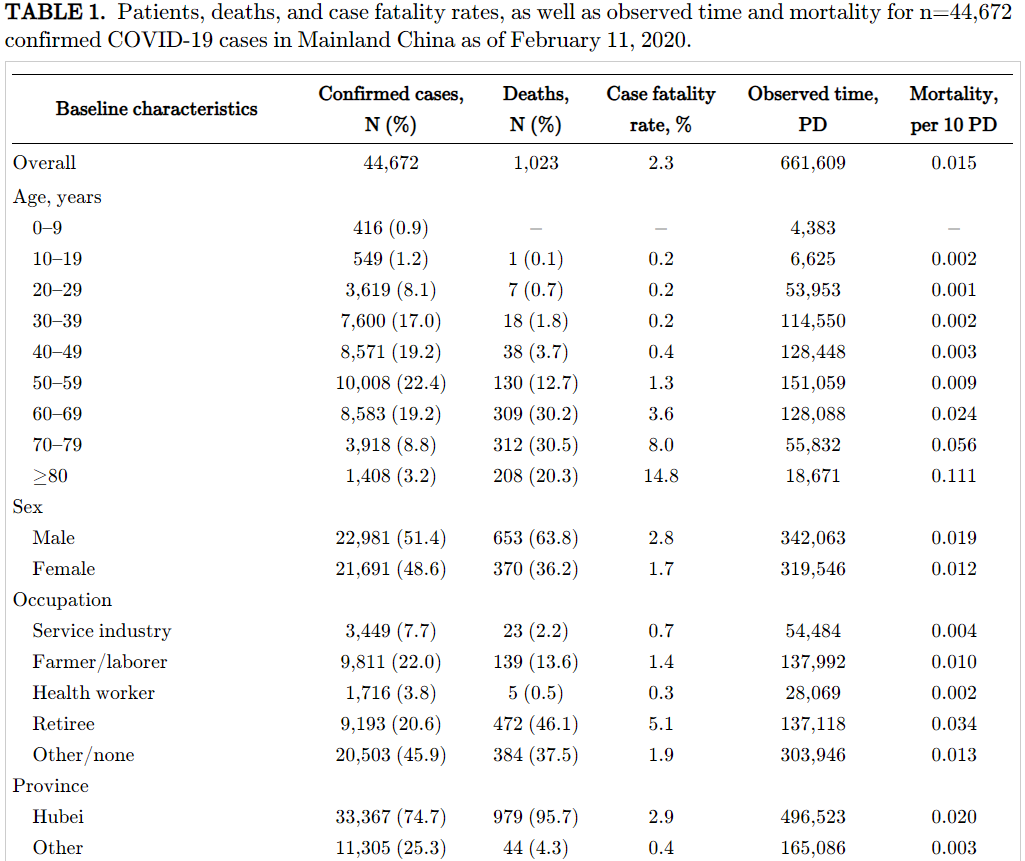
We illustrate the use of the package by estimating the average number of years by which people’s lives are shortened due to coronavirus. Using data from Table 1 of the paper that gives us the distribution of ages of people who died from COVID-19 in China, with conservative assumptions (assuming gender of the dead person to be male, taking the middle of age ranges) we find that people’s lives are shortened by
about 11 years on average. These estimates are conservative for one additional reason: there is likely an inverse correlation between people who die and their expected longevity. And note that given a bulk of the deaths are among older people, when people are more infirm, the quality adjusted years lost is likely yet more modest. Given that the last life tables from China are from 1981, we estimate the average number of years lost if people had the same profile as Americans. Using the most
recent SSA data, we find that number to be 16. Compare this to deaths from road accidents, the modal reason for death among 5-24 and 25-44 ages in the US. Male life expectancy in the US at 25 is another ~ 52 years.
Get Human Life Table data columns from HLD dataset
|
lowest_age |
highest_age |
middle_age |
n_deaths |
sex |
country |
year |
hld_country |
hld_age |
hld_sex |
hld_year |
hld_life_expectancy |
| 0 |
10 |
19 |
15 |
1 |
M |
CHN |
2020 |
CHN |
10 |
M |
1981 |
60.38 |
| 1 |
20 |
29 |
25 |
7 |
M |
CHN |
2020 |
CHN |
20 |
M |
1981 |
50.89 |
| 2 |
30 |
39 |
25 |
18 |
M |
CHN |
2020 |
CHN |
30 |
M |
1981 |
41.56 |
| 3 |
40 |
49 |
45 |
38 |
M |
CHN |
2020 |
CHN |
40 |
M |
1981 |
32.33 |
| 4 |
50 |
59 |
55 |
130 |
M |
CHN |
2020 |
CHN |
50 |
M |
1981 |
23.54 |
Note that the year we are matching to is 1981.
|
lowest_age |
highest_age |
middle_age |
n_deaths |
sex |
country |
year |
hld_country |
hld_age |
hld_sex |
hld_year |
hld_life_expectancy |
| 0 |
10 |
19 |
15 |
1 |
M |
CHN |
2020 |
CHN |
10 |
M |
1981 |
60.38 |
| 1 |
20 |
29 |
25 |
7 |
M |
CHN |
2020 |
CHN |
20 |
M |
1981 |
50.89 |
| 2 |
30 |
39 |
25 |
18 |
M |
CHN |
2020 |
CHN |
30 |
M |
1981 |
41.56 |
| 3 |
40 |
49 |
45 |
38 |
M |
CHN |
2020 |
CHN |
40 |
M |
1981 |
32.33 |
| 4 |
50 |
59 |
55 |
130 |
M |
CHN |
2020 |
CHN |
50 |
M |
1981 |
23.54 |
| 5 |
60 |
69 |
65 |
309 |
M |
CHN |
2020 |
CHN |
60 |
M |
1981 |
15.73 |
| 6 |
70 |
79 |
75 |
312 |
M |
CHN |
2020 |
CHN |
70 |
M |
1981 |
9.57 |
| 7 |
80 |
89 |
85 |
208 |
M |
CHN |
2020 |
CHN |
80 |
M |
1981 |
5.31 |
Assuming all the people who died were at the bottom of the age ranges
|
lowest_age |
highest_age |
middle_age |
n_deaths |
sex |
country |
year |
hld_country |
hld_age |
hld_sex |
hld_year |
hld_life_expectancy |
years_lost |
| 0 |
10 |
19 |
15 |
1 |
M |
CHN |
2020 |
CHN |
10 |
M |
1981 |
60.38 |
0.059022 |
| 1 |
20 |
29 |
25 |
7 |
M |
CHN |
2020 |
CHN |
20 |
M |
1981 |
50.89 |
0.348221 |
| 2 |
30 |
39 |
25 |
18 |
M |
CHN |
2020 |
CHN |
30 |
M |
1981 |
41.56 |
0.731261 |
| 3 |
40 |
49 |
45 |
38 |
M |
CHN |
2020 |
CHN |
40 |
M |
1981 |
32.33 |
1.200919 |
| 4 |
50 |
59 |
55 |
130 |
M |
CHN |
2020 |
CHN |
50 |
M |
1981 |
23.54 |
2.991398 |
| 5 |
60 |
69 |
65 |
309 |
M |
CHN |
2020 |
CHN |
60 |
M |
1981 |
15.73 |
4.751290 |
| 6 |
70 |
79 |
75 |
312 |
M |
CHN |
2020 |
CHN |
70 |
M |
1981 |
9.57 |
2.918710 |
| 7 |
80 |
89 |
85 |
208 |
M |
CHN |
2020 |
CHN |
80 |
M |
1981 |
5.31 |
1.079648 |
|
lowest_age |
highest_age |
middle_age |
n_deaths |
sex |
country |
year |
hld_country |
hld_age |
hld_sex |
hld_year |
hld_life_expectancy |
| 0 |
10 |
19 |
15 |
1 |
M |
CHN |
2020 |
CHN |
19 |
M |
1981 |
51.83 |
| 1 |
20 |
29 |
25 |
7 |
M |
CHN |
2020 |
CHN |
29 |
M |
1981 |
42.50 |
| 2 |
30 |
39 |
25 |
18 |
M |
CHN |
2020 |
CHN |
39 |
M |
1981 |
33.24 |
| 3 |
40 |
49 |
45 |
38 |
M |
CHN |
2020 |
CHN |
49 |
M |
1981 |
24.39 |
| 4 |
50 |
59 |
55 |
130 |
M |
CHN |
2020 |
CHN |
59 |
M |
1981 |
16.46 |
Assuming all the people who died were at the top of the age ranges
|
lowest_age |
highest_age |
middle_age |
n_deaths |
sex |
country |
year |
hld_country |
hld_age |
hld_sex |
hld_year |
hld_life_expectancy |
| 0 |
10 |
19 |
15 |
1 |
M |
CHN |
2020 |
CHN |
19 |
M |
1981 |
51.83 |
| 1 |
20 |
29 |
25 |
7 |
M |
CHN |
2020 |
CHN |
29 |
M |
1981 |
42.50 |
| 2 |
30 |
39 |
25 |
18 |
M |
CHN |
2020 |
CHN |
39 |
M |
1981 |
33.24 |
| 3 |
40 |
49 |
45 |
38 |
M |
CHN |
2020 |
CHN |
49 |
M |
1981 |
24.39 |
| 4 |
50 |
59 |
55 |
130 |
M |
CHN |
2020 |
CHN |
59 |
M |
1981 |
16.46 |
| 5 |
60 |
69 |
65 |
309 |
M |
CHN |
2020 |
CHN |
69 |
M |
1981 |
10.11 |
| 6 |
70 |
79 |
75 |
312 |
M |
CHN |
2020 |
CHN |
79 |
M |
1981 |
5.68 |
| 7 |
80 |
89 |
85 |
208 |
M |
CHN |
2020 |
CHN |
89 |
M |
1981 |
3.29 |
|
lowest_age |
highest_age |
middle_age |
n_deaths |
sex |
country |
year |
hld_country |
hld_age |
hld_sex |
hld_year |
hld_life_expectancy |
years_lost |
| 0 |
10 |
19 |
15 |
1 |
M |
CHN |
2020 |
CHN |
19 |
M |
1981 |
51.83 |
0.050665 |
| 1 |
20 |
29 |
25 |
7 |
M |
CHN |
2020 |
CHN |
29 |
M |
1981 |
42.50 |
0.290811 |
| 2 |
30 |
39 |
25 |
18 |
M |
CHN |
2020 |
CHN |
39 |
M |
1981 |
33.24 |
0.584868 |
| 3 |
40 |
49 |
45 |
38 |
M |
CHN |
2020 |
CHN |
49 |
M |
1981 |
24.39 |
0.905982 |
| 4 |
50 |
59 |
55 |
130 |
M |
CHN |
2020 |
CHN |
59 |
M |
1981 |
16.46 |
2.091691 |
| 5 |
60 |
69 |
65 |
309 |
M |
CHN |
2020 |
CHN |
69 |
M |
1981 |
10.11 |
3.053754 |
| 6 |
70 |
79 |
75 |
312 |
M |
CHN |
2020 |
CHN |
79 |
M |
1981 |
5.68 |
1.732317 |
| 7 |
80 |
89 |
85 |
208 |
M |
CHN |
2020 |
CHN |
89 |
M |
1981 |
3.29 |
0.668935 |
|
lowest_age |
highest_age |
middle_age |
n_deaths |
sex |
country |
year |
hld_country |
hld_age |
hld_sex |
hld_year |
hld_life_expectancy |
| 0 |
10 |
19 |
15 |
1 |
M |
CHN |
2020 |
CHN |
15 |
M |
1981 |
55.61 |
| 1 |
20 |
29 |
25 |
7 |
M |
CHN |
2020 |
CHN |
25 |
M |
1981 |
46.24 |
| 2 |
30 |
39 |
25 |
18 |
M |
CHN |
2020 |
CHN |
25 |
M |
1981 |
46.24 |
| 3 |
40 |
49 |
45 |
38 |
M |
CHN |
2020 |
CHN |
45 |
M |
1981 |
27.85 |
| 4 |
50 |
59 |
55 |
130 |
M |
CHN |
2020 |
CHN |
55 |
M |
1981 |
19.43 |
Assuming all the people who died were at the middle of the age ranges
|
lowest_age |
highest_age |
middle_age |
n_deaths |
sex |
country |
year |
hld_country |
hld_age |
hld_sex |
hld_year |
hld_life_expectancy |
| 0 |
10 |
19 |
15 |
1 |
M |
CHN |
2020 |
CHN |
15 |
M |
1981 |
55.61 |
| 1 |
20 |
29 |
25 |
7 |
M |
CHN |
2020 |
CHN |
25 |
M |
1981 |
46.24 |
| 2 |
30 |
39 |
25 |
18 |
M |
CHN |
2020 |
CHN |
25 |
M |
1981 |
46.24 |
| 3 |
40 |
49 |
45 |
38 |
M |
CHN |
2020 |
CHN |
45 |
M |
1981 |
27.85 |
| 4 |
50 |
59 |
55 |
130 |
M |
CHN |
2020 |
CHN |
55 |
M |
1981 |
19.43 |
| 5 |
60 |
69 |
65 |
309 |
M |
CHN |
2020 |
CHN |
65 |
M |
1981 |
12.46 |
| 6 |
70 |
79 |
75 |
312 |
M |
CHN |
2020 |
CHN |
75 |
M |
1981 |
7.26 |
| 7 |
80 |
89 |
85 |
208 |
M |
CHN |
2020 |
CHN |
85 |
M |
1981 |
4.02 |
|
lowest_age |
highest_age |
middle_age |
n_deaths |
sex |
country |
year |
hld_country |
hld_age |
hld_sex |
hld_year |
hld_life_expectancy |
years_lost |
| 0 |
10 |
19 |
15 |
1 |
M |
CHN |
2020 |
CHN |
15 |
M |
1981 |
55.61 |
0.054360 |
| 1 |
20 |
29 |
25 |
7 |
M |
CHN |
2020 |
CHN |
25 |
M |
1981 |
46.24 |
0.316403 |
| 2 |
30 |
39 |
25 |
18 |
M |
CHN |
2020 |
CHN |
25 |
M |
1981 |
46.24 |
0.813607 |
| 3 |
40 |
49 |
45 |
38 |
M |
CHN |
2020 |
CHN |
45 |
M |
1981 |
27.85 |
1.034506 |
| 4 |
50 |
59 |
55 |
130 |
M |
CHN |
2020 |
CHN |
55 |
M |
1981 |
19.43 |
2.469110 |
| 5 |
60 |
69 |
65 |
309 |
M |
CHN |
2020 |
CHN |
65 |
M |
1981 |
12.46 |
3.763578 |
| 6 |
70 |
79 |
75 |
312 |
M |
CHN |
2020 |
CHN |
75 |
M |
1981 |
7.26 |
2.214194 |
| 7 |
80 |
89 |
85 |
208 |
M |
CHN |
2020 |
CHN |
85 |
M |
1981 |
4.02 |
0.817361 |
Assume the Longevity is the Same as People in the US
|
lowest_age |
highest_age |
middle_age |
n_deaths |
sex |
country |
year |
ssa_age |
ssa_year |
ssa_life_expectancy |
| 0 |
10 |
19 |
15 |
1 |
M |
CHN |
2020 |
15 |
2022 |
60.39 |
| 1 |
20 |
29 |
25 |
7 |
M |
CHN |
2020 |
25 |
2022 |
51.03 |
| 2 |
30 |
39 |
25 |
18 |
M |
CHN |
2020 |
25 |
2022 |
51.03 |
| 3 |
40 |
49 |
45 |
38 |
M |
CHN |
2020 |
45 |
2022 |
33.32 |
| 4 |
50 |
59 |
55 |
130 |
M |
CHN |
2020 |
55 |
2022 |
24.94 |
|
lowest_age |
highest_age |
middle_age |
n_deaths |
sex |
country |
year |
ssa_age |
ssa_year |
ssa_life_expectancy |
years_lost |
| 0 |
10 |
19 |
15 |
1 |
M |
CHN |
2020 |
15 |
2022 |
60.39 |
0.059032 |
| 1 |
20 |
29 |
25 |
7 |
M |
CHN |
2020 |
25 |
2022 |
51.03 |
0.349179 |
| 2 |
30 |
39 |
25 |
18 |
M |
CHN |
2020 |
25 |
2022 |
51.03 |
0.897889 |
| 3 |
40 |
49 |
45 |
38 |
M |
CHN |
2020 |
45 |
2022 |
33.32 |
1.237693 |
| 4 |
50 |
59 |
55 |
130 |
M |
CHN |
2020 |
55 |
2022 |
24.94 |
3.169306 |
| 5 |
60 |
69 |
65 |
309 |
M |
CHN |
2020 |
65 |
2022 |
17.48 |
5.279883 |
| 6 |
70 |
79 |
75 |
312 |
M |
CHN |
2020 |
75 |
2022 |
10.92 |
3.330440 |
| 7 |
80 |
89 |
85 |
208 |
M |
CHN |
2020 |
85 |
2022 |
5.75 |
1.169110 |
Assume Everyone Lives Till 90
|
lowest_age |
highest_age |
middle_age |
n_deaths |
sex |
country |
year |
y90_life_expectancy |
| 0 |
10 |
19 |
15 |
1 |
M |
CHN |
2020 |
75 |
| 1 |
20 |
29 |
25 |
7 |
M |
CHN |
2020 |
65 |
| 2 |
30 |
39 |
25 |
18 |
M |
CHN |
2020 |
65 |
| 3 |
40 |
49 |
45 |
38 |
M |
CHN |
2020 |
45 |
| 4 |
50 |
59 |
55 |
130 |
M |
CHN |
2020 |
35 |
|
lowest_age |
highest_age |
middle_age |
n_deaths |
sex |
country |
year |
y90_life_expectancy |
years_lost |
| 0 |
10 |
19 |
15 |
1 |
M |
CHN |
2020 |
75 |
0.073314 |
| 1 |
20 |
29 |
25 |
7 |
M |
CHN |
2020 |
65 |
0.444770 |
| 2 |
30 |
39 |
25 |
18 |
M |
CHN |
2020 |
65 |
1.143695 |
| 3 |
40 |
49 |
45 |
38 |
M |
CHN |
2020 |
45 |
1.671554 |
| 4 |
50 |
59 |
55 |
130 |
M |
CHN |
2020 |
35 |
4.447703 |
| 5 |
60 |
69 |
65 |
309 |
M |
CHN |
2020 |
25 |
7.551320 |
| 6 |
70 |
79 |
75 |
312 |
M |
CHN |
2020 |
15 |
4.574780 |
| 7 |
80 |
89 |
85 |
208 |
M |
CHN |
2020 |
5 |
1.016618 |